

Everyone in the data world says, “Just add RAG and your AI agent will work”. Yet, the reality is that most AI agents work beautifully in controlled demos but collapse in real-world enterprise environments. They hallucinate, lose workflow state, misuse tools, and devolve into expensive autocomplete systems.
The primary culprit behind these failures is the industry's over-reliance on text-to-SQL generation. This approach has been conclusively proven to be inferior to using a semantic layer combined with a Large Language Model (LLM).
If you want to build AI systems that actually reason and scale, here is why your text-to-SQL models are failing, and a step-by-step guide on how to build the semantic core that fixes them.
The Fundamental Flaw: Why Text-to-SQL Fails for AI Agents
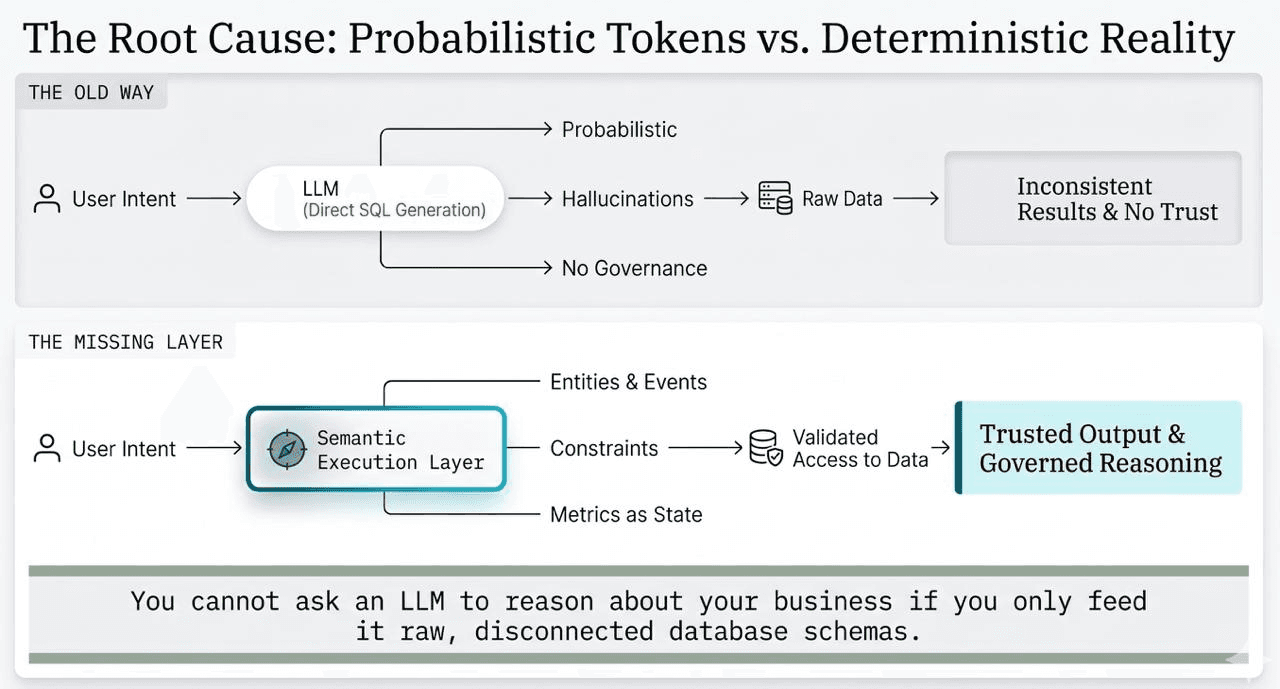
To understand why text-to-SQL fails, we have to look at how LLMs actually work. LLMs are probability engines, not reasoning engines. Their core function is predicting the next most likely token, which does not inherently equate to factual accuracy or logical business reasoning.
When an LLM is fed a raw database schema and asked to generate a SQL query, it relies entirely on semantic similarity and probabilistic guesswork. Because LLMs lack domain knowledge and do not understand your specific organizational rules, this guesswork leads to hallucinated joins, misapplied metrics, and broken integrations. Expecting an AI agent to understand raw data schemas is like asking someone to translate a complex legal document in Mandarin simply by showing them the character set—the fundamental meaning and context are missing.
The Solution: Moving to a Semantic Core (Ontology)
The companies successfully deploying Enterprise AI agents at scale are abandoning pure text-to-SQL. Instead, they are utilizing Ontologies and Knowledge Graphs.
A semantic layer acts as a "Rosetta Stone," translating raw, technical database language into an understandable business vocabulary. Rather than treating data as disconnected text, an ontology creates a formal, machine-readable model of your operational reality, defining the entities, properties, relationships, and permitted actions.
By doing this, AI agents move from probabilistic guessing to deterministic execution. When an agent answers a question, it traverses explicitly defined relationships within a semantic execution graph, yielding precise, highly accurate, and explainable multi-hop reasoning.
How to Build Your Own Semantic Layer and Ontology
Building an ontology is an incremental data intelligence process. You do not need to model your entire enterprise at once; you can start small, and the ontology will compound in value as it grows.
Here is a proven three-step architecture to build your own industrial ontology for AI agents:
Step 1: Establish the Semantic Model (The Business Dictionary)
Constructing an ontology requires a top-down approach, starting with a shared organizational language. This semantic model eliminates ambiguity by standardizing terms so that "equipment" or "customer" means the exact same thing to manufacturing, engineering, and finance.
You build this by creating a vocabulary dictionary consisting of:
Nouns: The core entities in your business (e.g., Equipment, Operator, Work Order).
Verbs: The relationships that connect them (e.g., Produces, Operates, Validates).
Adjectives: The states defining those entities (e.g., Active, Certified, Pending).
Step 2: Construct Domain-Specific Ontologies
Once your shared vocabulary is defined, you apply it to specific operational domains (like Quality, Production, or Maintenance). In this step, you determine the necessary level of detail and establish the strict rules and constraints for that specific context.
A robust domain ontology is built on four structural pillars:
Object Types: The categories of physical or abstract entities (like a "Machine" or a "Quality Inspection").
Properties: The static identifiers or dynamically computed characteristics of those objects (like a "Serial Number" or an "OEE Score").
Link Types: The explicit semantic connections detailing how entities interact (e.g., "Operator operates Machine")
Action Types: The permitted operations within the domain (e.g., "Schedule Maintenance"), including the preconditions that must be met and the resulting state changes.
Step 3: Populate the Knowledge Graph (Semantic Graph)
The final step is transitioning your framework from abstract structures to concrete, real-world data. The knowledge graph is the base data layer that populates your ontology.
In this step, you map your actual operational data to the properties defined in your ontology, instantiating the network. For instance, instead of the AI agent just understanding the abstract concept of a "CNC Machine," the knowledge graph generates the specific instance of "CNC Mill Station 7" running a specific batch of materials.
The Takeaway: Invest in Knowledge Architecture
The difference between a fragile text-to-SQL chatbot and a production-grade AI agent is not the size of the LLM. it is the knowledge architecture behind it.
If you want reliable, scalable AI, you must move beyond basic prompt engineering. By investing the time to build a semantic model, domain ontologies, and a populated knowledge graph, you provide the structured, governed context your AI needs to stop guessing probabilistically, and start reasoning deterministically at an enterprise scale.
KEEP READING
Explore more perspectives on AI, analytics, and enterprise intelligence.







